Where we are in this journey?
In Part 1, we established the mindset: everything fails, all the time. The question isn’t if your system will fail — it’s how badly.
In Part 2, we got specific: 70% of production outages are caused by application-level failures, not infrastructure. And we learned that detecting failures in under 30 seconds is the difference between a minor blip and a major incident.
Now in Part 3, we answer the critical question: once you know failures are coming and you can detect them fast, how do you stop them from becoming outages? The answer is a set of battle-tested resilience patterns. Let’s walk through them (one in detail and may be we can separate post for each of those) .
The Resilience Maturity Ladder
Most organizations are at Level 1 or 2. The patterns in this post move you to Level 3 and beyond. You don’t need to implement everything at once — start with the patterns that address your most common failure modes.
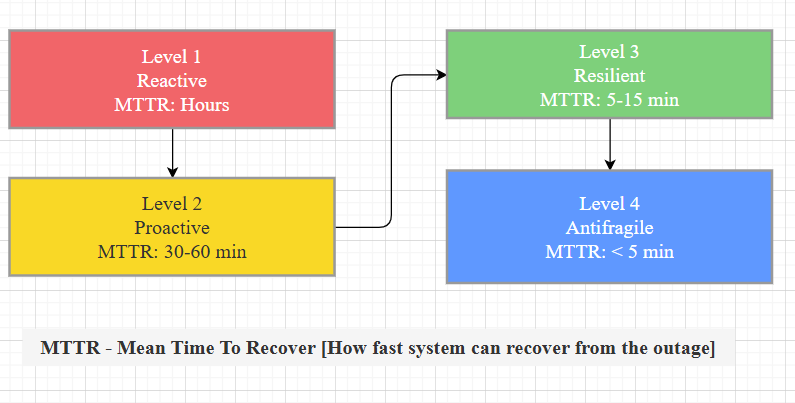 *Figure 1: Different maturity level
*Figure 1: Different maturity level
The Pattern Catalog
Think of resilience patterns as a defensive toolkit. Each pattern addresses a specific failure mode: Will have separate blogpost for each of those pattern later. below the high level of each of those pattern and thier usage.
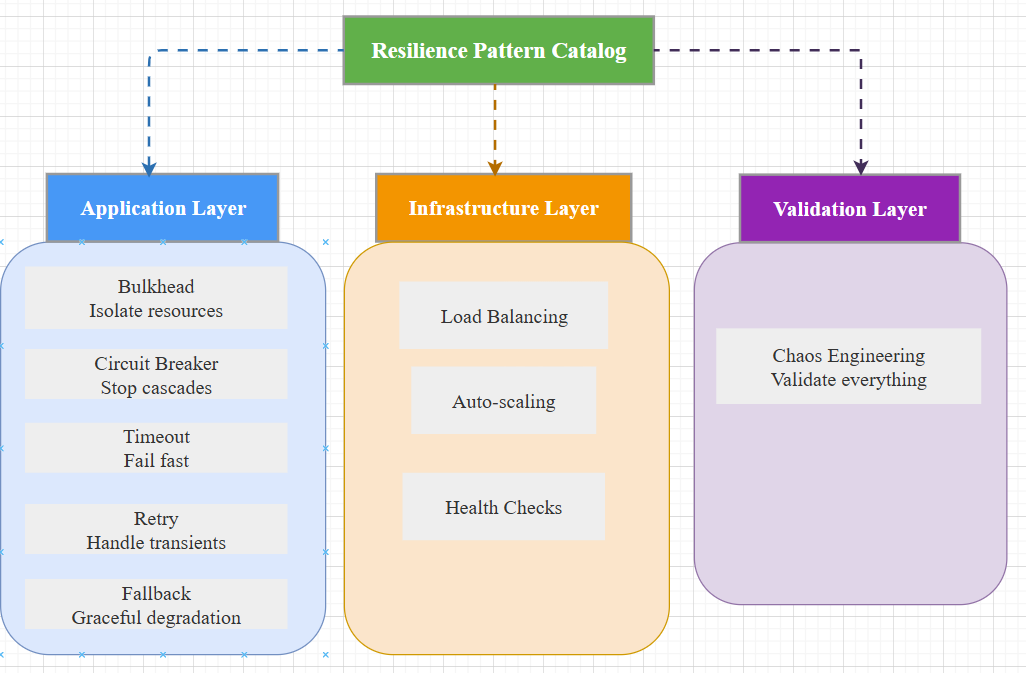 *Figure 1: Resiliency Catalogue
*Figure 1: Resiliency Catalogue
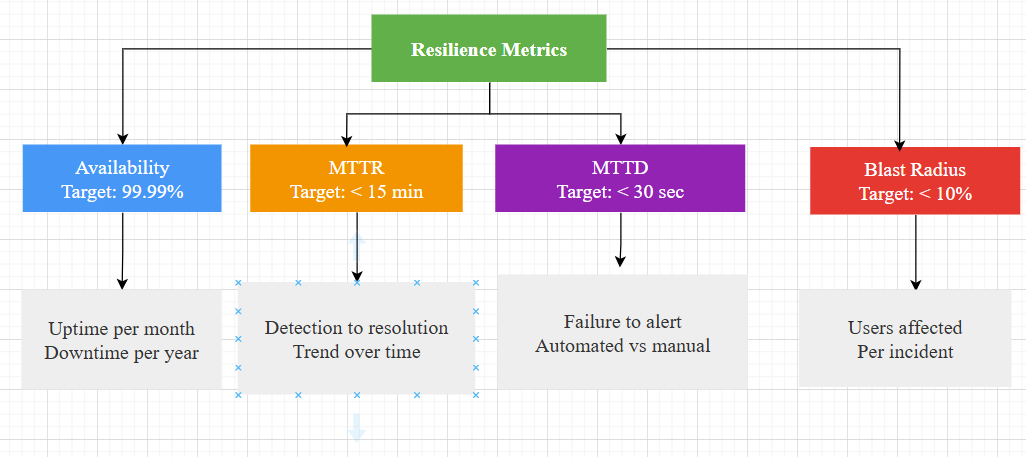 *Figure 1: Resiliency Matrix
*Figure 1: Resiliency Matrix
once we finish high level 4 parts of the series! we will be having separate blogs on each resiliency patterns
Key Takeaways
Circuit breakers stop cascades — one failing service shouldn’t take down everything else
Bulkheads isolate resources — separate pools mean one slow service can’t starve others
Timeouts fail fast — aggressive timeouts feel uncomfortable but prevent catastrophic pile-ups
Retries need jitter — exponential backoff without jitter creates thundering herds
Fallbacks beat hard failures — 90% functionality is infinitely better than 0%
Chaos engineering validates everything — patterns you haven’t tested are patterns you don’t trust
Start small, iterate — implement in phases, measure impact, improve continuously
What’s Next: The Ultimate Isolation Pattern
We’ve covered the mindset (Part 1), the detection (Part 2), and the patterns (Part 3). In Part 4, we bring it all together with Cell-Based Architecture — the infrastructure pattern that combines everything we’ve learned into a system that doesn’t just survive failures, but is fundamentally designed around them.
Next Will learn:
- How major tech companies achieve 99.99% availability at scale
- The infrastructure pattern that limits blast radius to 10% per incident When cells are the right answer — and when they’re overkill
- A practical implementation roadmap
- Real ROI analysis from production deployments
Part 4 drops next week. Follow along to get notified.
Your Turn
Which of these patterns would have the biggest impact on your system right now?
Circuit breakers to stop cascading failures?
Bulkheads to isolate your noisy neighbors?
Chaos engineering to find the gaps you don’t know about?