
After More than decade and half years of building & designing infrastructure & applications, what i realized is system resiliency is one of the crucial factor of any application.
This post is part 1 of resiliency series of building resiliency system.
Context
Once up on a time, there was an application serving millions of the customers on daily basis, bringing more business and work for the Organization. Suddenly one day one single glitch somewhere on the application or platform has blown the application, customer were facing issue on making payment or using their bank account.
Technical team started investing the issue and found the root cause:
“A deployment error. Old code that should have been deleted was accidentally activated. No circuit breakers. No kill switch. No blast radius containment.”
The lesson? In modern systems, failure isn’t a possibility — it’s a certainty. The question isn’t if your system will fail, but when and how badly.
This scenario reminds me a famous quote from Dr. Werner Vogels, CTO Amazon:
“Everything fails, all the time.”
In this four blogs series we will Embrace failure as a design principle, not an exception.
resiliency-part1-image1
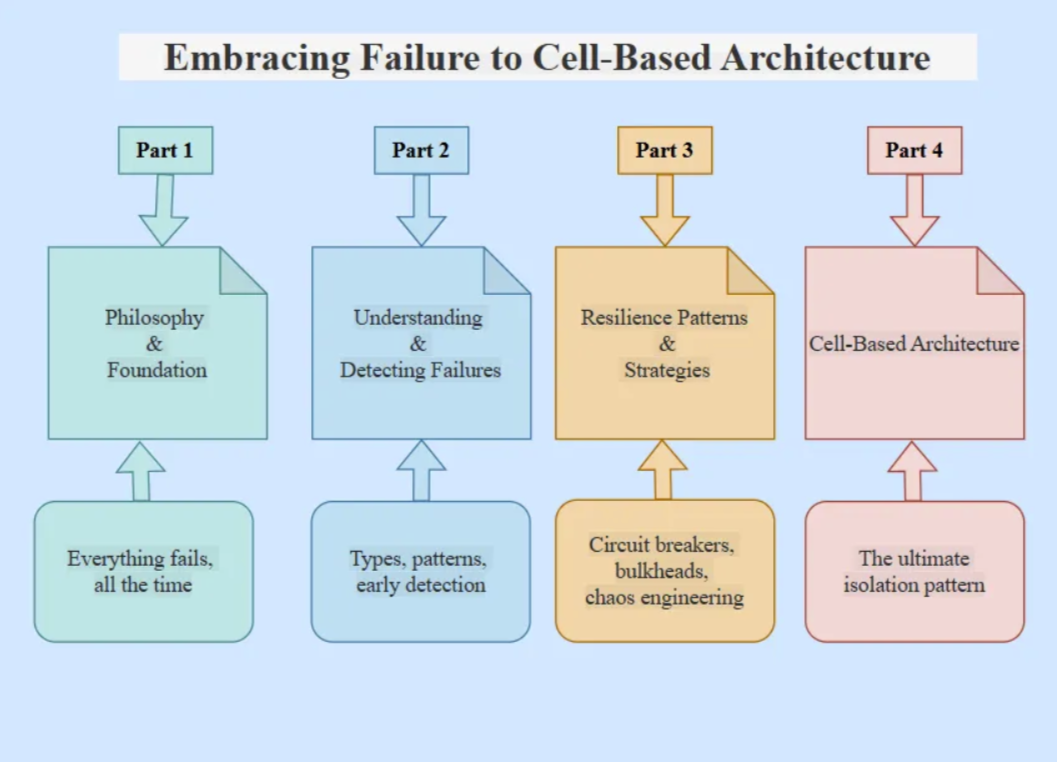 Figure 1: Each cell operates independently — failure in one cell doesn’t cascade
Figure 1: Each cell operates independently — failure in one cell doesn’t cascade
What kind of mindset does it need to build the resilient system?
The Resilience Paradigm Shift
The Business Case Downtime costs: $x,xxx/minute (average) Financial services: $xxxK/hour Reputation damage: Immeasurable Competitive advantage: 99.99% vs 99.9% = 52 min vs 8.7 hours/year Three Pillars of Resilience What really matters in case of resiliency?
Press enter or click to view image in full size
Resiliency Pillars Real-World Examples Netflix: Chaos Monkey (2011) — Revolutionary Amazon: Cell-based architecture Google: SRE practices Capital One: Multi-account isolation What are the key takeways from Part 1 Failure is inevitable, not exceptional Design for failure from day one Resilience is a competitive advantage Start with mindset, then tools Call to Action: “In Part 2, we’ll explore the anatomy of failures — what fails, why, and how to detect it early.”
Write on Medium Please like, subscribe and share with others — To master the resiliency in a systematic way.
References:
System Reliability and Availability - Google SRE Book — Chapter 3: Embracing Risk AWS Well-Architected Framework — Reliability Pillar Microsoft Azure — Reliability Patterns 2. Failure Cost Analysis
Gartner: Cost of Downtime Uptime Institute: Data Center Outages 3. Werner Vogels and Amazon’s Philosophy
All Things Distributed (Werner Vogels’ Blog) AWS re:Invent Keynotes
Have questions or want to discuss your application or infrastructure setup? Connect with me on LinkedIn.