The Million Dollor Question?
December 2021. AWS us-east-1 goes dark. Millions of applications offline. Estimated business impact: In millions per hour.
Your CIO/CTO asks: “Can this happen to us?”
You’ve implemented circuit breakers, bulkheads, timeouts. Your application layer is bulletproof. But here’s the uncomfortable truth:
Application patterns solve 48% of failures. Infrastructure failures? That’s the other 30%.
When the data center fails, when the availability zone goes offline, when the cloud region has an outage — your circuit breakers can’t help you.
This is where cell-based architecture enters.
What We’ve covered So Far
Part 1: Embracing failure as a design principle | https://cloudtoailearn.dev/posts/resiliency-series--long-part1/
Part 2: Anatomy of failures (application vs infrastructure) | https://www.linkedin.com/pulse/building-resilient-systems-series-part-2-narendra-makwana-jilge/
Part 3: Resilience patterns (circuit breakers, bulkheads, timeouts) | https://cloudtoailearn.dev/posts/resiliency-series--long-part3/
Coverage so far: 48% of failures (application layer only)
Part 4 (this post): Cell-based architecture for infrastructure isolation (6 Isolation Patterns?)
Target coverage: 78% of all failures (application + infrastructure)
What Is Cell-Based Architecture?
The Core Concept Cell = Complete, isolated replica of your entire application stack serving a subset of users or data.
Traditional Tech Stack: 1 stack → 100% users → 1 failure = 100% impact
Cell-Based Architecture: 10 cells → 10% users each → 1 failure = 10% impact
Four Core Principles
- Complete Isolation - Each cell contains all services, data, infrastructure
- Homogeneous Design - All cells identical (predictable, scalable)
- Sticky Routing - Customer always routes to same cell (data locality)
- Blast Radius Containment - Failure limited to one cell
The Problem Cell-Based Architecture Solves
Failure Coverage Analysis Application Failures (70%) - NOT solved by cells:
- Software bugs (35%)
- Configuration errors (15%)
- Deployment issues (10%)
- Resource exhaustion (5%)
- Dependencies (5%) → Solution: Resilience patterns (covered in Part 3)
Infrastructure Failures (30%) - SOLVED by cells:
- Hardware failures (12%)
- Network issues (8%)
- Cloud outages (5%)
- Data center issues (5%) → Solution: Cell-based architecture (this post)
Combined Coverage: 78% (cells + patterns together)
Cells are NOT a silver bullet. They solve infrastructure isolation, not application bugs. You must combine cells with resilience patterns for comprehensive coverage.
The Complexity Trap
The Over-Engineering Problem Common Mistake: “We have reliability issues. Let’s add a service mesh (Istio, Linkerd).”
Why It Fails:
- Service mesh adds 5-10ms latency per hop
- Sidecar overhead: +30% CPU/memory
- Operational complexity: 2x components to manage
- New failure modes: Mesh control plane, certificate rotation
- Cost increase: +40% infrastructure + operations
Right Approach: Application failures → Application patterns (circuit breakers, timeouts) Infrastructure failures → Infrastructure isolation (cells)
The RTO/RPO Right-Sizing Question
Critical Decision: Do You Even Need Cells? Cell-based architecture is 3-4x more expensive than active-passive.
Before you commit to cells, answer this:
What is your actual RTO/RPO requirement?
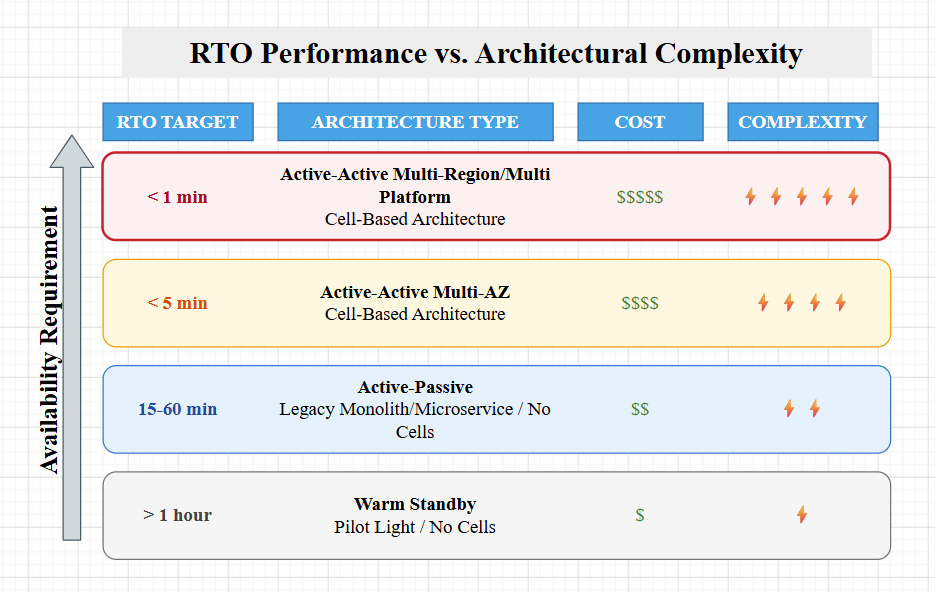
With the consideration we have asked the right question, team has understood all the consquences with the approach and tradeoff with different resiliency ask.
Let’s cover cell based Architecture Patterns (in this blog post will cover high level aspect and have follow post to explore each pattern in details in upcoming weeks.
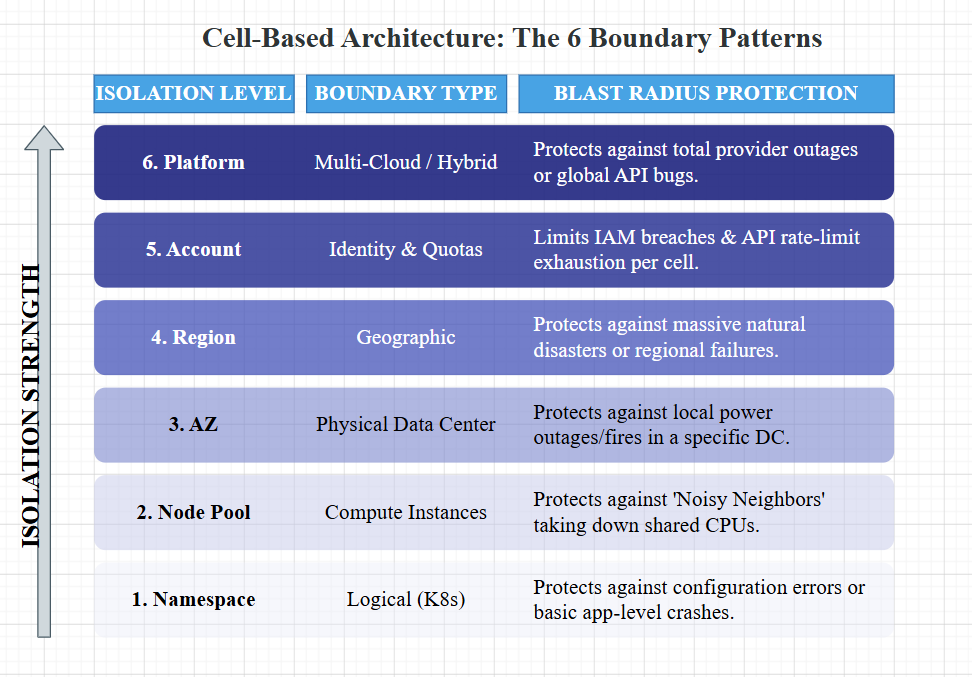
The 6 Isolation Boundaries
Logical Tier: Namespace Isolation (Best for micro-cells/K8s density).
Compute Tier: Node Pool Isolation (Prevents noisy neighbors).
Physical Tier: Availability Zone (DC Level) & Region (Geographic).
Sovereignty Tier: Account Isolation (Security/IAM) & Multi-Platform (The “Nuclear” option).
The Resilience Spectrum (RTO/RPO)
Mission Critical: Active-Active Multi-Region/Platform (<1 min RTO).
Standard Prod: Active-Active Multi-AZ (<5 min RTO).
Non-Critical: Warm Standby (>1 hour RTO).
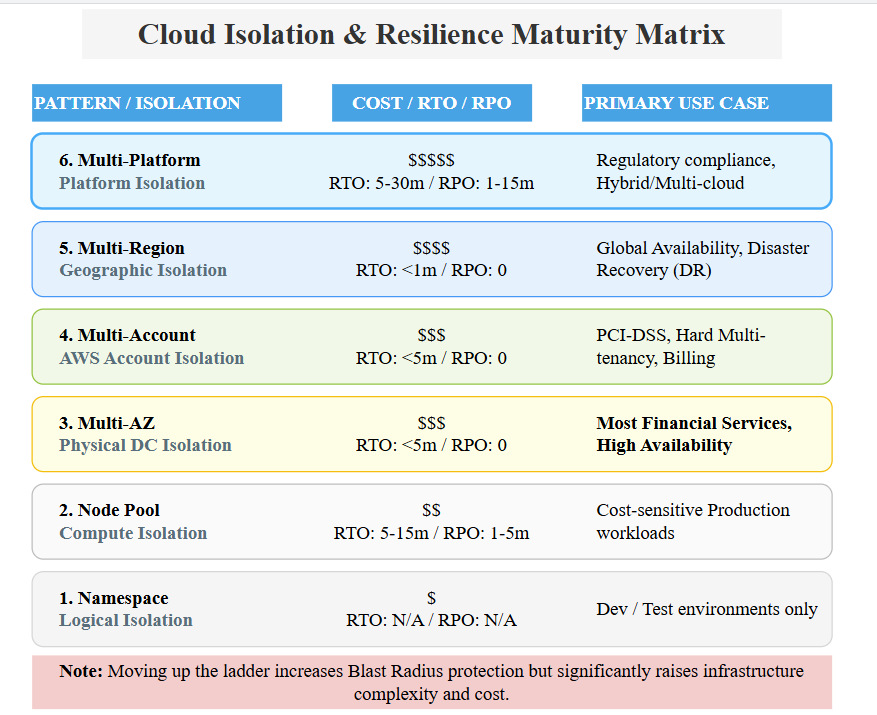
- The 3-Year TCO Analysis (based on the data collected by industry sources)
Key Insight: Resilience isn’t free. Moving from Multi-AZ to Multi-Region increases costs by ~36% due to data transfer overhead. Financial Comparison Chart CBA

Upcoming week, we will have further deep five on each cell based architecture pattern and thier usage. Like, subscribe and share with others.
Have questions or curious about anything on this post or want me to cover somehting specific in next post - leave a message or ? Connect with me on LinkedIn.
Keep Learning & Sharing.
References:
System Reliability and Availability - Google SRE Book — Chapter 3: Embracing Risk AWS Well-Architected Framework — Reliability Pillar Microsoft Azure — Reliability Patterns 2. Failure Cost Analysis Gartner: Cost of Downtime Uptime Institute: Data Center Outages 3. Werner Vogels and Amazon’s Philosophy All Things Distributed (Werner Vogels’ Blog) AWS re:Invent Keynotes
#CloudArchitecture #Resiliency #CellBased #SRE #SystemDesign #PlatformEngineering #CloudToAILearn #aws #SystemResilience #SRE #CloudArchitecture #CircuitBreaker #ChaosEngineering #AWS #DistributedSystems #FinancialServices #MicroServices #DomainDrivenDesign
💬 Comments